CanCore - Reliées les collections: une vue d'ensemble des approches
Norm Friesen Ph.D, 15 février, 2006
Introduction
La raison d'être du LOM, de CanCore et d'autres efforts de standardisation dans la e-formation est de faciliter le partage des ressources entre les collections ou les dépôts. Grâce au travail et au support de différents travaux traitant des standards, des collections ont été créées en utilisant les mêmes éléments et structure de métadonnées. Mais les métadonnées ne représentent qu'une seule pièce du puzzle de l'interopérabilité: Pour partager les ressources et réaliser les économies qui sont promises par les ressources pédagogiques, il est également important de relier ces collections ou dépôts en utilisant des protocoles communs. Ces protocoles décrivent comment les fiches (et les ressources) de contenus dans différents dépôts peuvent être recherchées et retrouvées.
On reconnaît généralement deux façons de relier des collections : par le moissonnage de métadonnées et par la recherche fédérée. Ces deux moyens de relier des dépôts sont en plusieurs points complémentaires sans être mutuellement exclusifs. Mais chaque approche a ses propres caractéristiques techniques, standards associées, avantages et inconvénients. En outre, chaque approche présente un certain nombre d'applications spécifiques et de solutions associées. (Ces applications, solutions, avantages et inconvénients sont tous indiqués en utilisant une gamme d'acronymes et de termes. Celles-ci sont définies dans un glossaire à la fin de ce document.) Ces solutions et leurs caractéristiques techniques font l'objet de ce document qui débute par une courte description des mécanismes généraux de moissonnage et de recherche fédérée, puis fournit une liste de leurs adaptations spécifiques et implantations.
Descendre l'échelle de l'intéropérabilité
|
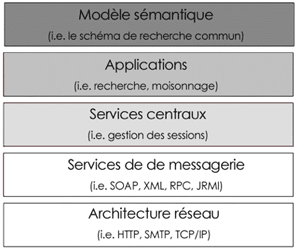
| Figure 1: Traduction libre de "Interoperability Stack," from Simon, et. al. 2005. Utilisé avec permission. |
Rechercher et trouver des fiches variées, de différents dépôts, implique un nombre significatif de couches d'infrastructure -- chaque couche présentant ses propres choix et défis. L'"échelle d'interopérabilité" présentée à droite (Figure 1, de Simon et al. 2005), montre ces couches de façon assez détaillée. Au niveau le plus élevé, elle présente "le modèle sémantique" c'est-à-dire la manière précise que les différentes métadonnées définissent le contenu de leurs éléments d'informations respectifs. Tous les protocoles considérés ici (à l'exception possiblement du RSS et d'ECL) peuvent manipuler une variété de modèles sémantiques, y compris CanCore/LOM et Dublin Core. Au deuxième niveau, le type général d'approche (question ou recherche fédérée ou moissonnage) entre en jeu. Cette préoccupation est centrale dans la section immédiatement en dessous. La prochaine couche, des "services centraux," fait référence aux mécanismes génériques, tels que la gestion d'authentification ou de session, qui peuvent être employés dans chaque protocole. Ces types de services sont généralement absents dans le moissonnage, mais sont souvent importants pour la recherche fédérée, qui (en partie à cause de sa synchronicité) définit souvent des mécanismes pour la gestion et la sécurité de session. Les "services de messagerie" font référence au codage des données dans les enregistrements et des commandes de réponses de recherche/recensement. XML et un certain nombre de ses dérivés (SOAP et XML RPC) sont actuellement les seules options qui ont fait l'objet d'une attention sérieuse dans les protocoles couverts dans ce document. Le dernier niveau de l'échelle d'interopérabilité se trouve l'architecture réseau qui implique un ou plusieurs des protocoles de base de transfert déjà largement en service sur l'Internet (par exemple pour les pages d'hypertexte et le courriel).
Recherche fédérée et moissonnage de métadonnées
La recherche fédérée et le moissonnage de métadonnées font référence à la collecte préprogrammée ou automatique de l'information descriptive provenant de sources distribuées. Cette collection ne se produit pas de façon fragmentaire, comme quand un utilisateur demande l'information, mais se produit de façon asynchrone et en lots. Ceci prédispose le moissonnage de métadonnées pour produire les collections qui sont des "catalogues collectifs" (avec le moissonnage complet des métadonnées des collections multiples ; voir le diagramme ci-dessous). Dans les contextes de la e-formation, où les métadonnées sont fortement détaillées et les enregistrements localisés -- qui incluent l'information de l'évaluation par les pairs ou des résultats d'apprentissage spécifiques -- peut acquérir le statut de ressources valables par lui-même. Le partage de tels enregistrements sans restriction qui est typique du moissonnage de métadonnées, peut présenter des défis en termes de politique de collection et de gestion de la propriété intellectuelle.
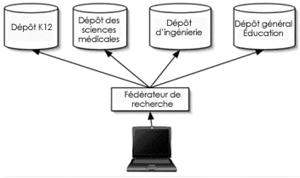
La recherche fédérée, d'autre part, produit les ensembles de résultats qui assemblent les enregistrements des contenus d'un certain nombre de sources séparées (un genre d'exemple de ceci est fourni par "MetaCrawler" ou "Dogpile" qui combinent des résultats d'une variété de moteurs de recherche). Cette solution d'interopérabilité est limitée par un facteur technique qui est également sa plus grande force : le synchrone. Le fait que les protocoles de recherche fédérée fonctionnent en temps réel et que les utilisateurs envoient et reçoivent des informations de recherche posent un certain nombre de limitations sur ces protocoles :
Moissonnage de métadonnées |
Recherche fédérée |
|
|
Figure 2: Organisation possible de dépôts utilisant le moissonnage |
Figure 3: Organisation possible des composantes dans un scénario de recherché fédérée.
|
Ce document fournit une vue d'ensemble de base des solutions spécifiques disponibles pour moissonner et effectuer des recherches fédérées. Des vues d'ensemble plus détaillées sont disponible, et sont recommandées :
Un certain nombre de solutions spécifiques liées au moissonnage de métadonnées et à la recherche fédérée sont énumérées ci-dessous. Pour chaque solution, un certain nombre de caractéristiques (par exemple origine/affiliation, normes associées, liaison des données [binding/message, etc...] sont énumérés).
Moissonnage de métadonnées
OAI PMH
Nom complet Open Archives Initiative Protocol for Metadata Harvesting Origine/Affilation Supporté par: Digital Library Federation, the Coalition for Networked Information, and from National Science Foundation Encodage/message HTTP-REQUEST; XML Sémantique Basée originalement sur Dublin Core, peut être adapté au LOM et autres sémantiques de métadonnées. Consulter: http://www.ukoln.ac.uk/metadata/dcmi-ieee/identifiers/ Langage d'interrogation Questions pour retrouver les enregistrements pour le moissonnage utilise l'encodage URI. Standards référencés/supportés URI Note: Définit des paramètres pour rechercher des informations sur des enregistrements disponibles, des caractéristiques de collection, et pour rechercher des enregistrements multiples ou individuels.
Pour plus d'information http://www.openarchives.org/ RSS
Nom complet Rich Site Summary (RSS 0.91), RDF Site Summary (RSS 0.9 and 1.0), Really Simple Syndication Origine Sources variées, incluant Netscape & Userland. Encodage /message XML Sémantique: il est compatible avec DublinCore, à la fois au sens large et spécifique. De l'assistance pour la sémantique du LOM est donnée pour les sites sommaires RDF à l'adresse : http://www.downes.ca/xml/rss_lom.htm Langage d'interrogation N/A Standards Referencés/Supportés XML ; OPML. Notez que ATOM est relié en un format parallèle. Note RSS est généralement implanté de façon à alerter les utilisateurs des nouveaux contenus dans les collections (que ce soit des métadonnées LOM, podcasts, etc.) Il n'inclue pas un éventail large de parameters de recherché tels que ceux qu'on retrouve dans OAI PMH, et les mécanismes n'ont pas pas été largement implantés pour retrouver et stocker une grande quantité d'enregistrement à teneur légale. Pour plus d'information Wikipedia entry for RSS (file format): http://en.wikipedia.org/wiki/RSS_(protocol)
Recherche fédérée
ECL
Nom complet eduSource Communication Layer Origine Edusource Project Encodage/Message XML/SOAP Sémantique LOM Langage d'interrogation: XQuery; peut aussi "mapper" en SQL Standards Référencés/supportés Utilise UDDI pour identifier et decrier les autres dépôts
Bridges/gateways sont disponibles pour d'autres solutions décrites dans ce document : OAI, SRW/SRU, et SQIPour plus d'information: http://ecl.iat.sfu.ca/ SQI
Nom complet Simple Query Interface Origine/Affiliation CEN-ISSS Learning Technologies (Also: Ariadne, CELEBRATE, Edutella, Elena, EduSource, ProLearn, Universal/EducaNext) Encodage/Message Peu importe Langage d'interrogation Peu importe Standards référencés/supportés
WSDL, Java Note Supporte à la fois la collection de données synchrone et asynchrone. Pour plus d'information: http://www.cetis.ac.uk/content2/20040227011926 SRW/SRU
Nom complet Search/Retrieve Web service / Search/Retrieve via URL Origine/Affiliation OCLC; Library of Congress Encodage/message SOAP/URL Langage d'interrogation: CQL ou XCQL Standards référencés/supportés Dans SRU, les interrogations sont encodées comme étant des URLs/URIs. Pour plus d'information: http://www.loc.gov/standards/sru/
http://www.loc.gov/standards/sru/srw/
Glossaire (a la http://fr.wikipedia.org):
OPML - Outline Processor Markup Language est un format XML permettant de regrouper et d'identifier les titres (outlines) d'un texte. Il a été initialement développé par Radio UserLand comme un format de fichier pour les applications utilisant ces titres. Depuis il a été adopté pour de multiples usages, le plus commun d'entre eux étant l'échange de listes de flux RSS entre les agrégateurs de news RSS. La norme OPML définit un "outline" d'une manière hiérarchique avec une liste d'attributs ordonnés.
RPC - Remote Procedure Call est un protocole permettant de faire des appels de procédures sur un ordinateur distant à l'aide d'un serveur d'application. Ce protocole est utilisé dans le modèle client-serveur et permet de gérer les différents messages entre ces entités.
SOAP - Simple Object Access Protocol est un protocole de RPC orienté objet bâti sur XML. Il permet la transmission de messages entre objets distants, ce qui veut dire qu'il autorise un objet à invoquer des méthodes d'objets physiquement situés sur une autre machine. Le transfert se fait le plus souvent à l'aide du protocole HTTP, mais peut également se faire par un autre protocole, comme SMTP.
SQL - Structured query language, traduisez Langage structuré de requêtes, est un langage informatique standard, destiné à interroger ou piloter (modifier contenu et structure) une base de données.
UDDI - acronyme de Universal Description Discovery and Integration, est une technologie d'annuaire basée sur XML et plus particulièrement destinée aux services web, notamment dans le cadre d'architectures de type SOA (Service Oriented Architecture). Un annuaire UDDI permet de localiser sur le réseau le [service Web] recherché. Il repose sur le protocole de transport SOAP.
URI - Un URI, de l'anglais Uniform Resource Identifier, soit littéralement identifiant uniforme de ressource, est un protocole mis en place pour le World Wide Web qui normalise la syntaxe de courtes chaînes de caractères désignant un nom ou une adresse d'une ressource, physique ou abstraite.
WSDL - Web Services Description Language. Il sagit d'une tentative de normalisation regroupant la description des éléments permettant de mettre en place l'accès à un service réseau (Service Web). Il fait notamment référence au langage XML et a été proposé en 2001 au W3C pour standardisation.
XML - Extensible Markup Language ou langage de balisage extensible est un standard du World Wide Web Consortium qui sert de base pour créer des langages de balisage spécialisés: c'est un « méta-langage ». En ce sens, XML permet de définir un vocabulaire et une grammaire associée sur base de règles formalisées.
XQUERY - XML Query ou XQuery est une spécification du W3C. XML Query est un langage de requête permettant d'extraire des informations d'un document XML. Sémantiquement proche de SQL, XML Query utilise la syntaxe XPath pour adresser des parties spécifiques d'un document XML.
Références
Simon, B. et. al. A Simple Query Interface for Interoperable Learning Repositories WWW 2005 , May 10-14, 2005 http://nm.wu-wien.ac.at/e-learning/interoperability/www2005-workshop-sqi-2005-04-14.pdf
Blinco, K. et. al. (2005). IMS Query Services White Paper Version 1.0 http://www.imsglobal.org/query/imsQueryServices.html