al. 2005. Used with permission.
CanCore - Connecting Collections: An overview of approaches
Dr. Norm Friesen; February 15, 2006
IntroductionThe raison d'être of the LOM, CanCore and other standardization efforts in e-learning is to enable easy or even seamless sharing of resources between collections or repositories. Thanks to much standards-based work and support, collections have been created using common metadata elements and structures. But that is only one piece in the "interoperability puzzle:" To realize resource sharing and cost savings that are promised by learning objects, it is important also to connect these collections or repositories using common protocols. These protocols describe the how the records (and resources) held by different repositories can be searched and retrieved.
Speaking very generally, there are two ways of accomplishing this: "metadata harvesting" and "federated searching." These two means of connecting repositiories are in many ways complementary and without being mutually exclusive. But each approach has its own technical characteristics, associated standards, and advantages and drawbacks. In addition, each approach has a number of specific applications and solutions associated with it. (These applications, solutions, advantages and drawbacks are all designated using a range of terms and acronyms. These are defined in a glossary towards the end of this document.) These solutions and their technical characteristics are the subject of this document. It begins with a brief with a brief description of the general mechanisms of metadata harvesting and federated searching, and then provides a listing of their specific adaptations and implementations.
Climbing down the Interoperability Stack
|
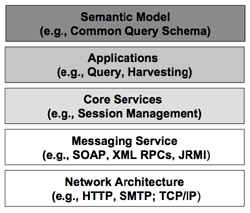
| Figure 1: "Interoperability Stack," from Simon, et. al. 2005. Used with permission. |
Searching and retrieving records of various kinds, from different repositories, involves a significant number of infrastructure layers --each layer presenting its own choices and challenges. The "interoperability stack" shown to the right (figure 1, from Simon, et. al. 2005), lays these out in some detail. On the highest level, it presents the "semantic model" --or the precise way that different metadata define the contents of their respective data elements. All of the protocols considered here (with the possible exception of RSS and ECL) can handle many different types of semantic models, including CanCore/LOM and Dublin Core. On the next level, the general type of approach (query or federated searching, or metadata harvesting) comes into play. This matter is the focus of the section immediately below. The next layer, "Core Services," refers to the generic mechanisms, such as authentication or session management, that can be used in each protocol. These types of services are generally absent in metadata harvesting, but are often important in federated searching, which (due in part to its synchronicity) often defines mechanisms for session management and security. "Messaging Services" refer to the encoding of record data and query/retrieval commands and responses. XML and a number of its derivatives (SOAP and XML RPC) are currently the only options given serious attention in the protocols covered here. At the bottom of the interoperability stack is network architecture, which involves one or more of the basic transport protocols already widely in use on the Internet (e.g. for hypertext pages and email).
Federated Search and Metadata Harvesting
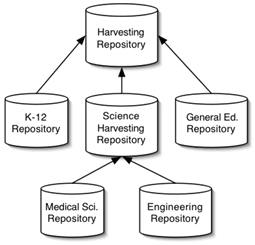
Metadata Harvesting refers to the pre-programmed or automatic collection of descriptive information from distributed sources. This collection does not occur piecemeal, as when an end user requests information, but occurs asynchronously and in batch form. This predisposes metadata harvesting to produce collections that are "union catalogues" (with the full metadata harvested from multiple collections; see diagram below). In e-learning contexts, highly detailed and localized metadata records --which include peer review information or specific learning outcomes-- can acquire the status of valuable resources in and of themselves. Sharing such records in the unrestricted manner typical of metadata harvesting can present challenges in terms of collection policy and intellectual property management.
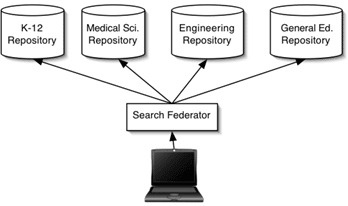
Federated searching, on the other hand, produces results sets that collate record contents from a number of separate sources (a kind of example of this is provided by "MetaCrawler" or "Dogpile" which combine results from a variety of search engines). This interoperability solution is limited by the one technical factor that is also its greatest strength: synchronicity. The fact that federated searching protocols operate in real time when end users are sending and receiving query information places a number of limitations on these protocols:
Metadata Harvesting |
Federated Searching |
|
|
Figure 2: Possible arrangement of repositories using harvesting
|
Figure 3: Possible arrangement of components in a federated search scenario.
|
This document provides a basic overview of specific solutions available for both harvesting and federated searching. Other, more detailed overviews are available, and are recommended:
Listed below are a number of specific solutions associated with metadata harvesting and federated searching. For each solution, a number of characteristics (e.g. origin/affiliation, associated standards, binding/messaging, etc.) are listed.
Metadata Harvesting
OAI PMH
| Full Name | Open Archives Initiative Protocol for Metadata Harvesting |
| Origin/Affilation | Supported by: Digital Library Federation, the Coalition for Networked Information, and from National Science Foundation |
| Binding/Messaging | HTTP-REQUEST; XML |
| Semantics | Originally based on Dublin Core, adaptable to the LOM and other metadata semantics. See: http://www.ukoln.ac.uk/metadata/dcmi-ieee/identifiers/ |
| Query language: | Queries to retrieve records for harvesting use URI encoding. |
| Other Standards referenced or supported | URI |
| Note: | Defines parameters for retrieving information about records available, collection characteristics, and for retrieving multiple and individual records. |
| For more information: | http://www.openarchives.org/ |
RSS
| Full Name | Rich Site Summary (RSS 0.91), RDF Site Summary (RSS 0.9 and 1.0), Really Simple Syndication |
| Origin | Various sources, including Netscape & Userland. |
| Binding/Messaging | XML |
| Semantics: | Either broadly or specifically compatible with Dublin Core. Support for LOM semantics is provided for RDF Site Summary at: http://www.downes.ca/xml/rss_lom.htm |
| Query language | N/A |
| Referenced/Supported Standards | XML ; OPML. Note that ATOM is a related, parallel format. |
| Note | RSS is generally implemented as a way of alerting users to new content in collections (whether it be LOM metadata, podcasts, etc.). It does not include a broad range of retrieval parameters such as those provided by OAI PHM, and has no widely-implemented mechanisms for retrieving and storing large/legacy record sets. |
| For more information | Wikipedia entry for RSS (file format): http://en.wikipedia.org/wiki/RSS_(protocol) |
Federated Search
ECL
| Full Name | eduSource Communication Layer |
| Origin | Edusource Project |
| Binding/Messaging | XML/SOAP |
| Semantics | LOM |
| Query language: | XQuery; can map to SQL |
| Referenced/Supported Standards | Utilizes UDDI to identify and describe other repositories.
Bridges/gateways are available to other solutions described in this document: OAI, SRW/SRU, and SQI |
| For more information: | http://ecl.iat.sfu.ca/ |
SQI
| Full Name | Simple Query Interface |
| Origin/Affiliation | CEN-ISSS Learning Technologies (Also: Ariadne, CELEBRATE, Edutella, Elena, EduSource, ProLearn, Universal/EducaNext) |
| Binding/Messaging | Any |
| Query language | Any |
| Referenced/Supported Standards | WSDL, Java |
| Note | Supports both synchronous and asynchronous data collection. |
| For more information: | http://www.cetis.ac.uk/content2/20040227011926 |
SRW/SRU
| Full name | Search/Retrieve Web service / Search/Retrieve via URL |
| Origin/Affiliation | OCLC; Library of Congress |
| Binding/Messaging | SOAP/URL |
| Query language: | CQL or XCQL |
| Referenced/Supported Standards | In SRU, queries are encoded as URLs/URIs. |
| For more information: | http://www.loc.gov/standards/sru/ http://www.loc.gov/standards/sru/srw/ |
Glossary (from http://en.wikipedia.org):
OPML - (Outline Processor Markup Language) is an XML format for outlines. Originally developed by Radio UserLand as a native file format for an outliner application, it has since been adopted for other uses, the most common being to exchange lists of RSS feeds between RSS aggregators. The OPML specification defines an outline as a hierarchical, ordered list of arbitrary elements.
RPC - (Remote Procedure Call) is a protocol that allows a computer program running on one host to cause code to be executed on another host without the programmer needing to explicitly code for this. When the code in question is written using object-oriented principles, RPC is sometimes referred to as remote invocation or remote method invocation.
SOAP - (Simple Object Access Protocol) is a protocol for exchanging XML-based messages over a computer network, normally using HTTP. SOAP forms the foundation layer of the web services stack, providing a basic messaging framework that more abstract layers can build on. SOAP facilitates the Service-Oriented architectural pattern.
SQL - (Structured Query Language) is the most popular computer language used to create, modify and retrieve data from relational database management systems. The language has evolved beyond its original purpose to support object-relational database management systems.
UDDI - (Universal Description, Discovery, and Integration) is a platform-independent, XML-based registry for businesses worldwide to list themselves on the Internet. UDDI is an open industry initiative (sponsored by OASIS) enabling businesses to discover each other and define how they interact over the Internet.
URI - (Uniform Resource Identifier) is an Internet protocol element consisting of a short string of characters that conform to a certain syntax. The string comprises a name or address that can be used to refer to a resource
WSDL - (Web Services Description Language) is an XML format published for describing Web services. This is an XML-based service description on how to communicate using the web service; namely, the protocol bindings and message formats required to interact with the web services listed in its directory.
XML - (Extensible Markup Language) is a W3C-recommended general-purpose markup language for creating special-purpose markup languages, capable of describing many different kinds of data. It is a simplified subset of SGML. Its primary purpose is to facilitate the sharing of data across different systems, particularly systems connected via the Internet.
XQuery - a query language (with some programming language features) that is designed to query collections of XML data. It is semantically similar to SQL.
References
Simon, B. et. al. A Simple Query Interface for Interoperable Learning Repositories WWW 2005 , May 10-14, 2005 http://nm.wu-wien.ac.at/e-learning/interoperability/www2005-workshop-sqi-2005-04-14.pdf
Blinco, K. et. al. (2005). IMS Query Services White Paper Version 1.0 http://www.imsglobal.org/query/imsQueryServices.html .