
Jutta Treviranus,
Director, Adaptive
Technology
Resource Centre
Director, Adaptive
Technology
Resource Centre
|
Jutta Treviranus, Director, Adaptive Technology Resource Centre |
CanCore: Standardizing for Access - Interview with Jutta Treviranus
Jutta Treviranus & Norm Friesen
November 30, 2005
Norm: I'm here with Jutta Treviranus, head or the Adaptive Technology Resource Centre and a Senior Research Associate at the Faculty of Information Studies at the University of Toronto. She is also a representative on working groups on accessibility in the W3C, IMS, Dublin Core and ISO/IEC JTC1/SC36.
Norm: Jutta, as a first question, I'll ask you about the Access for All Framework, the purposes it serves, and how it works with its two primary components: an "accessibility" specification for metadata and a related specification for the "Learner Information Profile."
Jutta: The "Access for All Framework" was initially developed in IMS (www.imsglobal.org), and the initial purpose was to provide a framework whereby content and user interfaces could be made accessible to individuals with disabilities. But in talking to many of experts and stakeholders associated with IMS, it became quite clear that, in fact, the type of framework that we had in mind could have a much larger purpose. So one of our first activities was to reframe what we meant by disability within the e-learning context. We decided to reframe it as follows: A disability is not something a person lacks; it is instead a mismatch between learner needs and the education delivered. It's not a personal trait, but a consequence of the relationship between the learner and the learning environment. And as such, "accessibility" emerges simply as the ability of the system to match the needs of the learner. So the Access for All Framework is two components or two sides of that match: the first side of the match is a common language to describe what a learner needs in a learning environment. This has been called the Accessibility Learner Information Profile (or ACCLIP). This language ensures that these needs are identified in very functional ways, so there is no identification of a disability, no personal information disclosed. It simply allows a statement to be articulated as follows: "In order to optimally learn, I need these methods of displaying things, these methods of controlling things, and these types of either content supplements or content enhancements or scaffolding or supports for learning." So that's the one half of the match. The other half of the match is the resource description or metadata; it is called the Accessibility Meta-Data Information Model (or ACCMD). It corresponds to the description of what the user needs, and identifies the characteristics of the resource that might or might not be able to meet those needs. So this is the equivalent of a large part of the user needs descriptions, but to be used to label the resource. In this way, a system that is delivering the resource can determine whether in fact there will be an appropriate match or what needs to be changed, disaggregated or transformed in order to make the match.
Norm: Are there ways in which the two specifications --metadata and learner profile-- can work independently of the other?
Jutta: Yes, and definitely that's happening. Certainly, the metadata and profile specifications have both been used independently of the one another. Accessibility profiles have been used in configuring multi-user workstations. The profile information is carried on a smart card, and when the smart car is inserted at a multi-user workstation, it configures the system, launches a browser, launches the assistive technology, and sets all of the preferences appropriate to the needs of the user. So there is, in fact, no resource description, because what we're configuring is the user interface, and the software applications and assistive technologies.
Norm: And the same thing could be done on the metadata side?
Jutta: Right.
Norm: One of the things that has been happening most recently is that these two standards are being turned from IMS specifications into standards in the context of ISO. In the process, their titles and some of their details are being changed. Can you tell me a little about that?
Jutta: Yes. So, we have taken the profile and metadata accessibility specifications and proposed a multi-part standard with a framework. This framework outlines how the matching I mentioned earlier would occur --how the description of the learner needs and preferences and the description of the resource. So at the moment it's a proposal for a three-part standard with the first part being the framework in general, the second part being the learner needs and preferences description, and the third part being the digital resource description. It's anticipated that there would be further parts, and those further parts would be used for things like descriptions of blended learning needs, non-digital resource labels or metadata, mobile environment device requirements, and the list goes on. There have been a number of members of ISO who have suggested other possible pieces or parts to this framework, other ways of both specifying what a learner needs and then articulating in some common way how a resource impact matches that.
Norm: Can you tell me what the main components of the resource description are? For example, how the elements are grouped, and what functions do those groupings reflect?
Jutta: There was quite a transition from IMS to ISO. When we did the consultations around the formulation of the IMS version of ACCMD the feedback that we got from the community was that it would be very difficult to get any additional metadata on any digital resource. People were not filling out t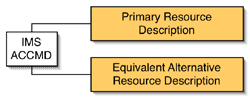 he metadata for resources that was already a part of existing standards. If we added anything further, it would be very difficult to get metadata creators to comply with it. So, in the IMS ACCMD, what we had created was a distinction between what is called the primary resource and equivalent alternative resource. The assumption was that the primary resource was the bulk of what people would be creating. What most people create is this primary resource, so the metadata requirements or load for these primary resources needed to be as light as possible. The assumption on the other side is that anyone that's creating an equivalent alternative would know about accessibility issues and would be sufficiently motivated and knowledgeable to fill out the metadata. So the largest number of the metadata elements in the IMS ACCMD were associated with the equivalent alternative. The primary resource had within it simply a pointer to any known equivalent alternative, and an identification of the transformability of the resource (either a text description or a statement generated by an accessibility checker that reported how easily this could be transformed): "Is this using CSS, is this using XSLT, can we re-style this, re-skin this, are you able to use either a keyboard or a mouse to access all of the functionality within this resource?" Those were the most basic questions that metadata needs to answer about a resource for accessibility purposes. And the assumption was that these basic metadata elements could be filled out by an automated process of some sort, not requiring human judgement or human intervention. The one thing that did require human judgement and a human to fill out the metadata was a report on what sense is used to process this resource - is this visual information, is this audio information, is this tactile information, and do you need text literacy in order to process this resource? So that was the extent of the metadata on a typical primary resource.
he metadata for resources that was already a part of existing standards. If we added anything further, it would be very difficult to get metadata creators to comply with it. So, in the IMS ACCMD, what we had created was a distinction between what is called the primary resource and equivalent alternative resource. The assumption was that the primary resource was the bulk of what people would be creating. What most people create is this primary resource, so the metadata requirements or load for these primary resources needed to be as light as possible. The assumption on the other side is that anyone that's creating an equivalent alternative would know about accessibility issues and would be sufficiently motivated and knowledgeable to fill out the metadata. So the largest number of the metadata elements in the IMS ACCMD were associated with the equivalent alternative. The primary resource had within it simply a pointer to any known equivalent alternative, and an identification of the transformability of the resource (either a text description or a statement generated by an accessibility checker that reported how easily this could be transformed): "Is this using CSS, is this using XSLT, can we re-style this, re-skin this, are you able to use either a keyboard or a mouse to access all of the functionality within this resource?" Those were the most basic questions that metadata needs to answer about a resource for accessibility purposes. And the assumption was that these basic metadata elements could be filled out by an automated process of some sort, not requiring human judgement or human intervention. The one thing that did require human judgement and a human to fill out the metadata was a report on what sense is used to process this resource - is this visual information, is this audio information, is this tactile information, and do you need text literacy in order to process this resource? So that was the extent of the metadata on a typical primary resource.
The equivalent alternative description matched almost exactly the corresponding part of the ACCLIP that describes content, specifically the alternative senses that could be used to access the content. These equivalent alternative elements described things like 'This is a visual alternative to audio,' 'This is an audio alternative to visual,' or any combination or variant of that. And of course within that it is important to differentiate between the precise kinds of audio alternatives or visual alternatives or textual alternatives. The intent here is that if you have a primary resource that says it has visual information and you have a learner who says 'I cannot process, or I want an alternative to, visual information --for example, an audio type or a text type,' then the equivalent alternative resource would declare what type of alternative it was, and also the details of that alternative - 'I'm an English caption,' 'I'm an enhanced caption,' or a verbatim caption, or at a reduced reading level, or whatever, so it's that type of detail that's in the IMS ACCMD.
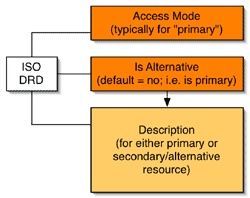 The change that was made to those two standards, or to that standard, when we moved to ISO, was because we were wanting to bind it to Dublin Core and to IEEE-LOM, and because of the structures within or the constraints within Dublin Core, it was felt that we should not make that distinction between an equivalent alternative, and a primary, within the information model itself. That would be part of the implementation, so we'd merged those two; there are now no longer the two types of records - it's one record and you would use one portion of it depending upon what type of resource you're describing. The other thing that was done is, because we're looking at implementation within IEEE-LOM and, more specifically, within Dublin Core, the hierarchy was somewhat flattened. So DRD is a much flattened version of the ACCMD.
The change that was made to those two standards, or to that standard, when we moved to ISO, was because we were wanting to bind it to Dublin Core and to IEEE-LOM, and because of the structures within or the constraints within Dublin Core, it was felt that we should not make that distinction between an equivalent alternative, and a primary, within the information model itself. That would be part of the implementation, so we'd merged those two; there are now no longer the two types of records - it's one record and you would use one portion of it depending upon what type of resource you're describing. The other thing that was done is, because we're looking at implementation within IEEE-LOM and, more specifically, within Dublin Core, the hierarchy was somewhat flattened. So DRD is a much flattened version of the ACCMD.
Norm: Right. Can you tell me just a little bit about how you're working together with CanCore on this project, this standard?
Jutta: With CanCore, what we are hoping to do, or what we are in the process of doing, is to create the same sorts of CanCore supports, the supports that CanCore has, for the rest of the metadata it supports, but for the DRD, specifically for the second part of the match, the digital resource description. We are creating the practical implementation guidelines, finding examples, also providing comments on the vocabulary and how it should be implemented, and generally sufficient resources and guidance and information to be able to implement the DRD in concert with the other CanCore metadata guidance.
Norm: Right. Excellent. That sounds wonderful. I've learned a lot. Thank you very much.