
Jutta Treviranus,
directrice, Centre
de ressources des
technologies
adaptatives
directrice, Centre
de ressources des
technologies
adaptatives
|
Jutta Treviranus, directrice, Centre de ressources des technologies adaptatives |
CanCore: Normaliser pour faciliter l'accès - Entrevue avec Jutta Treviranus
Jutta Treviranus & Norm Friesen
Traduit par : Karin Lundgren & Suzanne Lapointe
Le 30 novembre 2005
Norm: Je suis au Centre de ressources des technologies adaptatives avec la directrice Jutta Treviranus qui est aussi chercheure associée principale à la Faculté des Sciences de l'information à l'université de Toronto. Elle est aussi membre des groupes de travail W3C, IMS, Dublin Core et ISO/IEC JTC1/SC36 sur l'accessibilité.
Norm: Jutta, ma première question porte sur le cadre conceptuel de l' « Accès pour Tous » notamment quel est son but et comment sont reliées ses deux composantes primaires: la spécification des métadonnées concernant l'accessibilité et celle concernant le « Profil Informationnel de l'Apprenant ».
Jutta: À l'origine, le projet de l' "Accès pour tous" a été élaboré en relation avec IMS (www.imsglobal.org ) et le but initial était de fournir un cadre conceptuel pour rendre disponibles le contenu et les interfaces usagers aux individus ayant des handicaps. Mais, en discutant avec plusieurs experts et autres parties prenantes associées à IMS, il s'avérait, en fait, que le concept que nous avions en tête pouvait avoir une mission beaucoup plus large. Alors, nous avons revu notre concept de 'handicap pour mieux le définir dans le contexte du eLearning. Nous l'avons redéfini comme suit : Un handicap n'est pas vu comme quelque chose qui manque à une personne; c'est plutôt un mauvais appariement entre les besoins de l'apprenant et la formation livrée. Ce n'est pas une caractéristique personnelle, mais une conséquence de la relation entre l'apprenant et l'environnement d'apprentissage. Ainsi, le concept d'accessibilité émerge simplement comme la capacité du système d'apparier les besoins de l'apprenant. Alors, le concept d'« Accès pour tous » comporte deux composantes ou facettes en relation avec l'appariement : la première composante est un langage commun pour décrire ce dont l'apprenant a besoin dans l'environnement. Cette composante a été nommée « Le profile d'information d'accessibilité de l'apprenant (Accessibility Learner Information Profile)» (ou ACCLIP). Ce langage garantit que les besoins de l'apprenant sont identifiés d'une manière très fonctionnelle. Il ne concerne pas l'identification d'un handicap. Aucune information personnelle n'est révélée. Ce langage permet simplement de formaliser un énoncé comme suit : 'Pour apprendre d'une façon optimale, j'ai besoin de ces types d'affichage, de contrôle de l'environnement, de formats de contenu, de contenu additionnel, de supports à l'apprentissage. C'est ça la première composante de l'appariement. L'autre composante concerne la description de la ressource ou les métadonnées et est appelée « Le modèle d'information des métadonnées d'accessibilité » (Accessibility Meta-Data Information Model or ACCMD). Celui-ci correspond à la description de ce dont l'usager a besoin, et identifie les caractéristiques de la ressource qui peuvent ou ne peuvent pas répondre à ses besoins. Ceci équivaut en grande partie à la description des besoins de l'usager, mais pour étiqueter la ressource. Ce faisant, le système qui livre une ressource peut déterminer si en fait cette ressource correspond aux besoins de l'apprenant et identifier ce qui doit être modifié, retranché ou transformé pour apparier la ressource aux besoins énoncés.
Norm: Est-ce que ces deux spécifications - métadonnées et profil de l'apprenant - peuvent être utilisées indépendamment l'une de l'autre ?
Jutta: Oui, et définitivement c'est cela qui arrive dans la pratique. Certainement, les deux spécifications, métadonnées et profil de l'apprenant, ont été utilisées indépendamment l'une de l'autre. Des profils d'accessibilité ont été utilisés pour configurer des postes de travail multi-usagers. L'information d'un profil est stockée sur une carte à puce intelligente, et quand cette carte est insérée dans un poste de travail multi-usagers, elle configure automatiquement le système, lance un fureteur, lance la technologie d'assistance, et définit toutes les préférences appropriées aux besoins de l'usager. Alors, en fait, il n'y a pas de description de ressource per se, parce que ce qui est configuré c'est l'interface usager, les applications logiciels ainsi que les technologies d'assistance.
Norm : Et la même chose pourraient être appliquées par rapport à la partie des métadonnées ?
Jutta : C'est cela.
Norm: Ce qui est arrivé dernièrement, c'est que ces deux spécifications ont été transformées. De spécifications IMS, elles sont devenues des normes dans le contexte d'ISO. Au cours de ce processus, certains titres et détails ont été modifiés. Pouvez-vous élaborer sur cet aspect ?
Jutta: Oui. Alors, à partir de ces deux spécifications, « profil de l'apprenant » et les « métadonnées », nous avons proposé une norme multi-parties incluant un cadre conceptuel. Ce cadre conceptuel explique comment pourrait se réaliser l'appariement dont j'ai parlé tout à l'heure, entre la description des besoins de l'apprenant et ses préférences et la description de la ressource. Présentement, c'est une proposition d'une norme en trois parties, la première présentant un cadre général, la seconde comprenant la description des besoins et préférences de l'apprenant, et la troisième étant la description de la ressource numérisée. On s'attend à ce que d'autres parties s'ajoutent par exemple pour décrire des besoins propres à une situation d'apprentissage hybride (blended learning), des étiquettes ou métadonnées d'objets non numérisés, des ressources requises dans un environnement mobile, etc., etc. Des membres d'ISO ont suggéré d'autres parties et d'autres façons de spécifier ce dont un apprenant a besoin et de formuler simplement comment la ressource répond à ses besoins
Norm: Pouvez-vous m'expliquer les principales composantes de la description d'une ressource ? Par exemple, comment les éléments sont-ils regroupés et quelle est la fonction de ces regroupements ?
Jutta: La transition d'IMS à ISO était assez laborieuse. Le résultat de nos consultations sur la formulation de la version IMS d'ACCMED auprès de la communauté d'usagers indiquait clairement que ça serait très difficile d'ajouter des métadonnées supplémentaires sur une ressource numérisée, parce que déjà les gens n'indiquaient même pas les métadonnées des normes existantes. 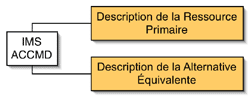 Si nous proposons d'ajouter quoi que ce soit d'autres, il va être très difficile pour les éditeurs de métadonnées de s'y conformer. Alors, dans IMS ACCMED, nous avons fait une distinction entre ce que nous appelons « une ressource primaire » et «une alternative équivalente», l'hypothèse étant que la ressource primaire constitue l'ensemble de ce que les éditeurs indiqueront. Ce que la majorité des gens crée est cette ressource primaire, alors les métadonnées exigées pour les ressources primaires doivent représenter une charge minimale. L'hypothèse réciproque est que celui qui va créer la ressource alternative est une personne qui sera au fait de la problématique de l'accessibilité et qui sera assez motivé et connaissant pour fournir ces métadonnées. Alors, la plupart des éléments de métadonnée dans l'IMS ACCMD étaient, dans la version antérieure, dans la catégorie des éléments équivalents de la ressource alternative. La ressource primaire comprenait tout simplement un pointeur à une ressource alternative équivalente, et une identification de l'adaptation possible de la ressource (soit une description textuelle ou un énoncé généré par un vérificateur d'accessibilité qui émet un rapport sur la facilité de transformation) : « Est-ce que la ressource utilise CSS, XSLT, pouvons-nous refaire le style, le look, est-ce qu'on peut utiliser soit le clavier soit la sourit pour accéder à toutes les fonctionnalités de cette ressource? » Ce sont les premières questions auxquelles les métadonnées d'une ressource doivent pouvoir répondre concernant l'accessibilité de la ressource. L'hypothèse était aussi que ces métadonnées devaient être générées automatiquement d'une façon ou une autre, ne demandant aucune jugement ou intervention humaine. L'élément qui requiert un jugement humain et une personne pour entrer les métadonnées, c'est un rapport signalant quel élément sensoriel est sollicité par l'utilisation de cette ressource - est-ce que l'information est visuelle, auditive, tactile et a-ton besoin d'être capable de lire un texte pour comprendre cette ressource. Alors, voilà les questions se rapportant aux métadonnées d'une ressource primaire typique.
Si nous proposons d'ajouter quoi que ce soit d'autres, il va être très difficile pour les éditeurs de métadonnées de s'y conformer. Alors, dans IMS ACCMED, nous avons fait une distinction entre ce que nous appelons « une ressource primaire » et «une alternative équivalente», l'hypothèse étant que la ressource primaire constitue l'ensemble de ce que les éditeurs indiqueront. Ce que la majorité des gens crée est cette ressource primaire, alors les métadonnées exigées pour les ressources primaires doivent représenter une charge minimale. L'hypothèse réciproque est que celui qui va créer la ressource alternative est une personne qui sera au fait de la problématique de l'accessibilité et qui sera assez motivé et connaissant pour fournir ces métadonnées. Alors, la plupart des éléments de métadonnée dans l'IMS ACCMD étaient, dans la version antérieure, dans la catégorie des éléments équivalents de la ressource alternative. La ressource primaire comprenait tout simplement un pointeur à une ressource alternative équivalente, et une identification de l'adaptation possible de la ressource (soit une description textuelle ou un énoncé généré par un vérificateur d'accessibilité qui émet un rapport sur la facilité de transformation) : « Est-ce que la ressource utilise CSS, XSLT, pouvons-nous refaire le style, le look, est-ce qu'on peut utiliser soit le clavier soit la sourit pour accéder à toutes les fonctionnalités de cette ressource? » Ce sont les premières questions auxquelles les métadonnées d'une ressource doivent pouvoir répondre concernant l'accessibilité de la ressource. L'hypothèse était aussi que ces métadonnées devaient être générées automatiquement d'une façon ou une autre, ne demandant aucune jugement ou intervention humaine. L'élément qui requiert un jugement humain et une personne pour entrer les métadonnées, c'est un rapport signalant quel élément sensoriel est sollicité par l'utilisation de cette ressource - est-ce que l'information est visuelle, auditive, tactile et a-ton besoin d'être capable de lire un texte pour comprendre cette ressource. Alors, voilà les questions se rapportant aux métadonnées d'une ressource primaire typique.
La description de l'alternative équivalente correspond presque exactement à la partie d'ACCLIP qui décrit le contenu, et surtout les alternatives sensorielles possibles pour accéder au contenu. Ces éléments alternatifs équivalents décrivent des choses comme p.ex. : 'Ceci est une alternative visuelle à l'audio', 'Ceci est l'alternative audio au visuel', ou n'importe laquelle combinaison du genre. De plus, il est important de différencier la sorte d'alternative audio, visuelle ou textuelle. Le but ici est que si vous avez une ressource primaire qui dit qu'elle a de l'information visuelle et que vous avez un apprenant qui dit 'Je ne peux pas m'approprier cela, ou bien je voudrais une alternative à l'information visuelle - par exemple, un audio ou un texte, ' alors la ressource alternative pourrait déclarer le type d'alternative en question et les détails de celle-ci - Je suis en version anglaise , ou une version améliorée, ou une version verbatim, ou d'un niveau de lecture inférieure etc.... C'est ce niveau de détail que traite l'IMS ACCMED. La modification apportée à ces deux normes, ou à cette norme, au moment d'adhérer à ISO, provenait du fait que nous voulions la lier à 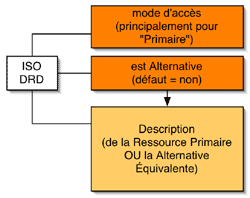 Dublin Core ainsi qu'au IEEE-LOM, et à cause des structures et limites de Dublin Core, nous avions senti qu'il valait mieux ne pas faire cette distinction entre une alternative équivalente et une ressource primaire dans le modèle d'information. Au lieu, ceci ferait partie de l'implémentation, avec le résultat que les deux spécifications ont été fusionnées ; dorénavant il n'y a plus deux types d'enregistrements - c'est un seul enregistrement et vous utilisez une portion selon le type de ressource que vous êtes en train de décrire. L'autre chose qui a été faite, parce que ce qui nous concerne c'est l'implémentation de IEEE-LOM et, plus spécifiquement, de Dublin Core, la hiérarchie a été quelque peu nivelée. Finalement, la DRD (Description d'une ressource numérisée) est une version moins hiérarchisée comparée à la spécification ACCMED.
Dublin Core ainsi qu'au IEEE-LOM, et à cause des structures et limites de Dublin Core, nous avions senti qu'il valait mieux ne pas faire cette distinction entre une alternative équivalente et une ressource primaire dans le modèle d'information. Au lieu, ceci ferait partie de l'implémentation, avec le résultat que les deux spécifications ont été fusionnées ; dorénavant il n'y a plus deux types d'enregistrements - c'est un seul enregistrement et vous utilisez une portion selon le type de ressource que vous êtes en train de décrire. L'autre chose qui a été faite, parce que ce qui nous concerne c'est l'implémentation de IEEE-LOM et, plus spécifiquement, de Dublin Core, la hiérarchie a été quelque peu nivelée. Finalement, la DRD (Description d'une ressource numérisée) est une version moins hiérarchisée comparée à la spécification ACCMED.
Norm: Correct. Pouvez-vous élaborer un petit peu sur votre façon de travailler avec CanCore sur ce projet, cette norme?
Jutta: Avec CanCore, ce que nous espérons faire, ou ce que nous sommes en train de faire, c'est de créer la même sorte d'appui que CanCore fournit pour les autres types de métadonnées, à l'exception de DRD, surtout pour la deuxième partie de l'appariement, notamment la description de la ressource numérisée. Nous sommes en train de créer les lignes directrices pour faciliter l'implémentation du DRD, trouver des exemples, fournir des commentaires sur le vocabulaire, son implantation, suffisamment d'informations pour implanter DRD de concert avec les autres soutiens aux métadonnées du CanCore.
Norm: Correct. Excellent. Merci beaucoup, j'ai beaucoup appris de cette entrevue.